小型Hadoop集群的數(shù)據(jù)分層調(diào)度處理算法分析
隨著大數(shù)據(jù)技術(shù)的快速發(fā)展,小型Hadoop集群在企業(yè)數(shù)據(jù)處理及存儲服務(wù)中的應(yīng)用日益廣泛。數(shù)據(jù)分層調(diào)度處理算法作為Hadoop集群中的核心組成部分,對提高數(shù)據(jù)處理效率、優(yōu)化資源分配具有重要意義。本文旨在分析小型Hadoop集群中數(shù)據(jù)分層調(diào)度處理算法的原理、特點(diǎn)及其在計(jì)算機(jī)數(shù)據(jù)處理及存儲服務(wù)中的應(yīng)用。
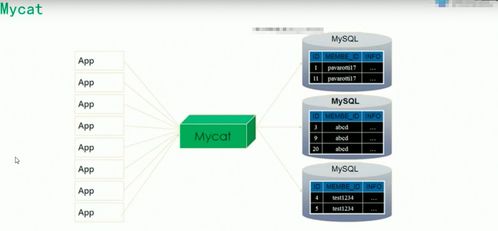
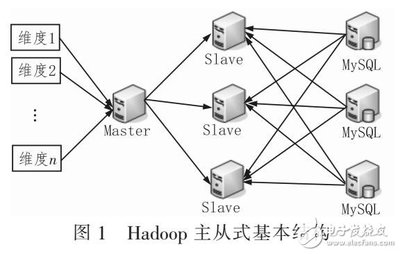
數(shù)據(jù)分層調(diào)度處理算法通過對數(shù)據(jù)按訪問頻率、重要性等維度進(jìn)行分層,將熱點(diǎn)數(shù)據(jù)與冷數(shù)據(jù)分別存儲于不同層次的存儲介質(zhì)中,以實(shí)現(xiàn)資源的高效利用。在小型Hadoop集群中,由于計(jì)算和存儲資源相對有限,分層調(diào)度算法通常結(jié)合Hadoop的HDFS和YARN組件,通過智能調(diào)度策略(如基于優(yōu)先級的調(diào)度、動態(tài)資源分配)來平衡負(fù)載,避免資源瓶頸。
常見的數(shù)據(jù)分層調(diào)度算法包括基于時(shí)間局部性的LRU(最近最少使用)算法、基于訪問頻率的分層策略以及結(jié)合機(jī)器學(xué)習(xí)方法的自適應(yīng)調(diào)度算法。在小型集群中,這些算法能夠根據(jù)數(shù)據(jù)訪問模式動態(tài)調(diào)整數(shù)據(jù)分布,例如將頻繁訪問的數(shù)據(jù)保留在高速存儲層(如SSD),而將冷數(shù)據(jù)遷移至低成本存儲層(如HDD)。這不僅提升了數(shù)據(jù)讀取速度,還降低了存儲成本。
在計(jì)算機(jī)數(shù)據(jù)處理及存儲服務(wù)中,數(shù)據(jù)分層調(diào)度處理算法的應(yīng)用顯著提高了服務(wù)質(zhì)量和系統(tǒng)可靠性。例如,在實(shí)時(shí)數(shù)據(jù)分析場景中,通過分層調(diào)度,小型Hadoop集群可以快速響應(yīng)高優(yōu)先級任務(wù),減少延遲;在批處理任務(wù)中,算法通過合理分配資源,確保大規(guī)模數(shù)據(jù)處理的效率。同時(shí),結(jié)合容錯(cuò)機(jī)制,這些算法還能在節(jié)點(diǎn)故障時(shí)自動調(diào)整數(shù)據(jù)分布,保障服務(wù)的連續(xù)性。
小型Hadoop集群在實(shí)施數(shù)據(jù)分層調(diào)度時(shí)也面臨挑戰(zhàn),如算法復(fù)雜度帶來的額外開銷、分層策略的調(diào)優(yōu)難度等。未來,隨著邊緣計(jì)算和云原生技術(shù)的發(fā)展,數(shù)據(jù)分層調(diào)度算法將更加智能化,例如引入強(qiáng)化學(xué)習(xí)進(jìn)行動態(tài)優(yōu)化,以進(jìn)一步提升小型集群在數(shù)據(jù)處理及存儲服務(wù)中的競爭力。
數(shù)據(jù)分層調(diào)度處理算法是小型Hadoop集群高效運(yùn)行的關(guān)鍵,其在計(jì)算機(jī)數(shù)據(jù)處理及存儲服務(wù)中的應(yīng)用不僅優(yōu)化了資源利用,還推動了大數(shù)據(jù)技術(shù)的普及與創(chuàng)新。未來的研究應(yīng)聚焦于算法的輕量化與自適應(yīng)能力,以應(yīng)對日益復(fù)雜的數(shù)據(jù)處理需求。
如若轉(zhuǎn)載,請注明出處:http://www.rationalsoft.com.cn/product/923.html
更新時(shí)間:2026-01-20 00:55:08